How LLMs Fail on Product Identity, And How to Fix It with Barcodes, MPNs, and Deduplication Rules


LLMs are excellent at summarizing and classifying text, but they are unreliable at product identity: deciding whether two listings are the same physical item, a close substitute, or a lookalike bundle. In affiliate commerce, that identity mistake is not academic, it becomes the wrong image, the wrong price comparison, or a broken trust moment on the page.
Affiliate.com is designed for the part LLMs struggle with: normalized, searchable product data at scale, spanning more than 30 networks, 20,000 merchant programs, and over a billion products. The fix is a workflow where the LLM helps with intent and categorization, while identifiers, filters, and deduplication enforce identity and publishing correctness.
Why LLMs break on product identity
They over trust names and images
Merchants rewrite titles constantly. The same product can appear under multiple names across networks and merchants, and search by product name alone often returns a wide range of listings with different titles.
An LLM reading two titles that share brand and a few keywords will often assume equivalence. That is how you end up comparing a bundle to a standalone product, or the current generation to the prior generation.
They collapse lookalikes into “same enough”
Some products look identical at a glance but are not the same: bundles versus standalone items, private label variants, and subtle model updates that require a different identifier to distinguish.
An LLM’s similarity judgment tends to treat these as “same enough.” Your users, and your conversion rate, will not.
The identity hierarchy: what to trust first
Affiliate.com’s product fields support an identity hierarchy that is more reliable than text similarity.
Barcode is the cross merchant truth anchor
Barcodes can verify that two listings from two different networks refer to the same product. That makes them the best default for comparisons, best offer widgets, and anything where you plan to rank merchants.
MPN and SKU are precision tools inside a merchant catalog
SKUs or MPNs are a precise way to identify a specific product from a specific merchant. Use them when you are validating one merchant listing, debugging a mismatch, or building a merchant scoped collection.
Brand helps narrow fast, but it is not identity
Brand normalization is valuable for filtering and narrowing, but brand alone cannot tell you whether two listings are the same model, size, or generation. Treat brand as a fast scope control, not the final identity verdict.
The fix: a practical LLM plus Affiliate.com workflow
Here is a reliable pattern that keeps the LLM in its strength zone while preventing identity failures.
Step 1: Use the LLM for intent, not equivalence
Ask the LLM to extract structured intent from a brief or a SERP cluster:
- target category and subcategory
- must have attributes (size, color, material)
- exclusion rules (no refurbished, no bundles)
Then stop. Do not let the LLM decide “same product.”
Step 2: Discover broadly with the any field
Use the any field for exploration because it searches across multiple product fields at once, including names, descriptions, brands, and categories. It is explicitly useful when products are inconsistently named across networks and when you want to start broad before layering filters.
Step 3: Collapse to identity with barcode, then choose deduplication
When you move from exploration to publishing, switch from text to identifiers:
- If you have a barcode, query by barcode to pull the exact same product across multiple merchants.
- Decide deduplication based on the page promise.
Deduplication is the control that determines whether you group identical products into a single result or show each listing separately. If enabled, the system clusters matching product offers and selects a single representative record. If disabled, you get all variants and offers, which is essential for offer comparison.
Applied example: prevent a “wrong model” comparison
Imagine your LLM drafts a module for “wireless noise canceling headphones” and recommends a specific model. Two merchant listings look nearly identical, but one is last year’s revision.
Identity safe workflow
- Start with any field to find candidates, then add brand to narrow.
- For the chosen candidate, pull its barcode, then run a barcode search to retrieve the exact product across merchants.
- Keep deduplication off while you verify merchants, prices, and availability for the same barcode.
- Layer publishing filters:
- currency for comparability
- in stock to avoid dead clickouts
- sort by final price or discount depending on your promise
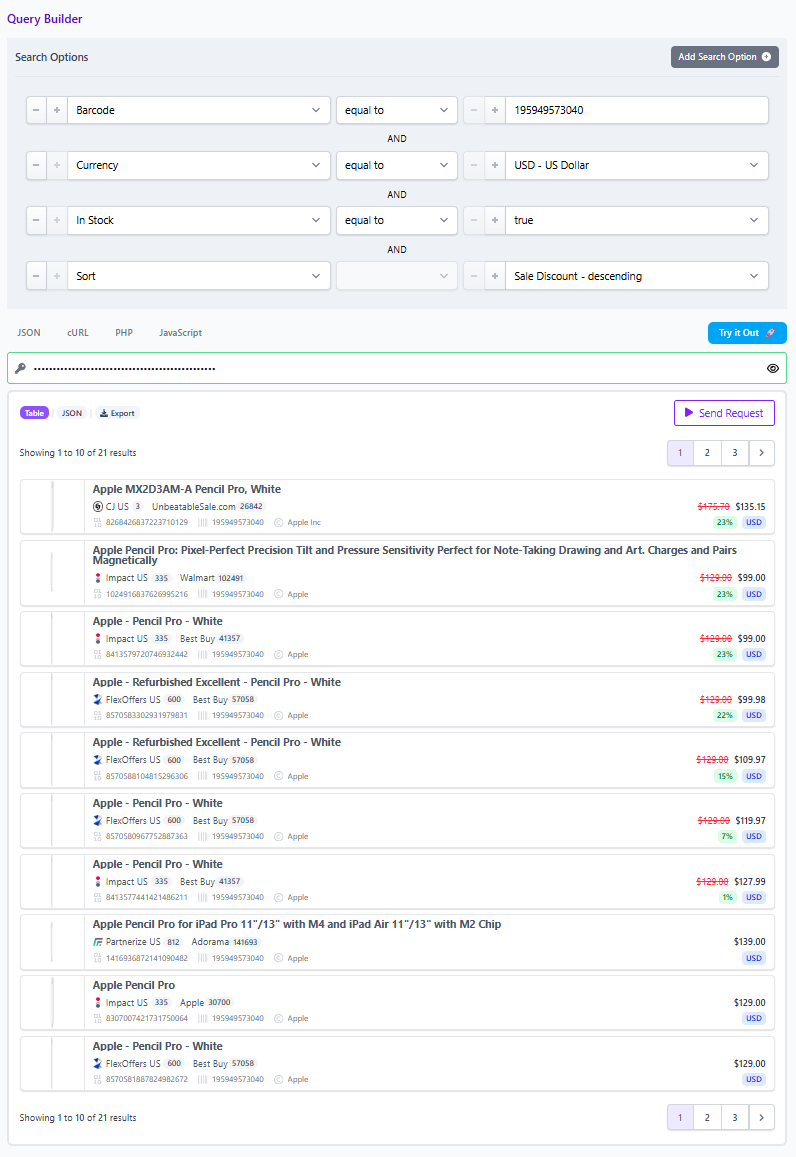
Affiliate.com’s pricing fields support this directly: regular price, final price, and discount allow you to validate whether something is truly on sale and to sort or filter by real price drop.
If you instead let the LLM “match” by title similarity, you risk ranking a different MPN or GTIN as if it were the same item, which breaks trust immediately.
Checklist: production rules that keep LLMs safe
Identity rules
- Use barcode for cross merchant equivalence whenever available.
- Use SKU or MPN for merchant scoped precision and debugging.
- Treat brand and name as narrowing tools, not final match criteria.
Display rules
- Deduplication on for clean browse lists and curated variety.
- Deduplication off for offer tables and true merchant comparisons.
Deal correctness rules
- Compare final price to regular price before labeling something a deal.
- Use discount thresholds to avoid weak promotions in “on sale” modules.
- Avoid price guarantees, and recommend verifying at the merchant.
Treat Query Builder as your human readable spec
The fastest way to operationalize this is to prototype the logic in Affiliate.com’s Query Builder, which lets you choose from over 30 search fields and then share the query as a link that reopens and populates the specified products. That shared query becomes the spec your LLM prompts, your content team, and your implementation can all reference.
Use the LLM to propose, use identifiers to confirm, use deduplication and filters to publish. That division of labor is how you get AI speed without AI identity mistakes.'